九游体育 国产GPU首获环球顶级推理框架「原生门票」: MUSA合入SGLang干线


机器之机杼剪部
若是只看这场 Meetup 的嘉宾名单,你粗略会先猜测外洋芯片巨头,或者某家国际 AI 基础设施公司。

毕竟,SGLang、TileLang、Triton 、Mooncake…… 这些今天大模子推理栈里最活跃、也最有存在感的开源名堂,险些齐有中枢斥地者来到现场。
但信得过把这群东说念主聚到整个的,简直是摩尔线程。
这才是这件事最值得看的地点。它阐述一件事:国产 GPU 厂商开动不仅仅追着生态跑,而是打入了环球主流开源 AI 软件栈,成为共建者。
近日,摩尔线程举办「SGLang × MUSA Meetup」,共享了其与 SGLang 社区及 MUSA 生态协同鼓动的最新发达。
自上个月 DeepSeek V4 发布后,摩尔线程第一时刻基于 SGLang 开源推理框架,成效完成了 DeepSeek V4 的齐备运行考证,并起首买通了从硬件架构中枢狡计引擎邻接、热门算子支捏,再到端到端部署考证的系统化适配链路。
另一项关节发达是,摩尔线程 MUSA 后端已厚爱加入 SGLang 官方支捏体系,相关代码也已成效合入 SGLang 干线,取得了这一环球顶级开源推理框架的「原生支捏」。
这意味着不仅是 DeepSeek V4,从 Qwen、GLM、MiniMax 到 Wan,越来越多主流大模子的推理加快材干,齐正在向国产算力生态原生灵通。
拥抱开源推理框架
摩尔线程作念了什么
在 AI 技巧栈中,SGLang 是聚拢大模子与底层硬件的推理就业框架,是让顶尖 AI 信得过落地成 App 的关节一环。自 2025 年起,SGLang 开动走向通用硬件适配,不绝加入了对 AMD、英特尔芯片的支捏。
这次摩尔线程代码合入 SGLang 干线,意味着摩尔线程依然与国际主流芯片站在了兼并阵列,厚爱踏进 SGLang 官方后端矩阵。
基于这一官方支捏体系,斥地者在使用 SGLang 运行大谈话模子及多模态推理任务时,依然不错径直调用摩尔线程全功能 GPU,完竣无需再依赖任何第三方适配层。
为什么摩尔线程能作念到这一步?摩尔线程 CTO 张钰勃在这场技巧共享上的致辞中给出了谜底:藏身「通用狡计」,以 MUSA(Meta-computing Unified System Architecture)灵通架构拥抱开源生态。
他强调,摩尔线程不走禁闭阶梯,而是坚捏底层狡计平台的信得过通用与高度长入。一方面,通用架构能撑捏从物理宇宙仿真、数字孪生到具身智能的异日技巧演进,不为立异设限;另一方面,通过全居品线「长入」的请示集与架构模范,确保软件生态能够捏续千里淀与积贮。
针对斥地者最为热心的「生态挪动」痛点,张钰勃直言:「摩尔线程秉捏灵通的气派,MUSA 在接口联想上最猛进度复用了斥地者闇练的 GPU 编程民俗。咱们不但愿孤苦创造一套禁闭的生态,而所以零学习资本,全面融入现存的茂密生态。」
这种「零学习资本」的答允,正真贯通切地反馈在摩尔线程与 SGLang 的工程落地中。

自本年 1 月起,摩尔线程向 SGLang 提交 issue,提供增多 MUSA 支捏的齐备阶梯图和任务拆分,筹划涵盖:在 runtime 部分对 LLM 的支捏,AOT Kernel 的支捏,多模态生成的支捏,Docker、CI、release 的支捏等等。
当今,AI 斥地者使用国产 GPU 后,不需要再作念复杂底层篡改,就能径直用上环球目下起初进、最高效的大模子转念框架。目下,SGLang 已支捏通过源码格式进行装配,并可按照文档径直完成部署,能够径直在摩尔线程 MTT S5000 智算卡上闲居运行,并支捏了险些整个的基础模子,无需任何二次代码篡改,显赫缩小了斥地者的算力挪动门槛。
当年将代码挪动到国产 GPU 需要手动搜索和修改大齐的 torch.cuda 原语。针对这个问题,摩尔线程斥地了 torchada 适配层,收场了「一次 import,全包处置」。斥地者只需引入适配包,即可自动将大模子的显存管制、流处理等 CUDA 接口无缝桥接到 MUSA 平台上,大幅缩小了适配与珍贵资本。
同期,针对无法径直挪动或性能欠安的算子,摩尔线程应用开源的 MATE(MUSA AI Tensor Engine)高性能算子库进行替换和加快,其提供了高性能 Attention 与 GEMM 算子,已对接 FlashAttention、FlashMLA、DeepGEMM 等主流接口。
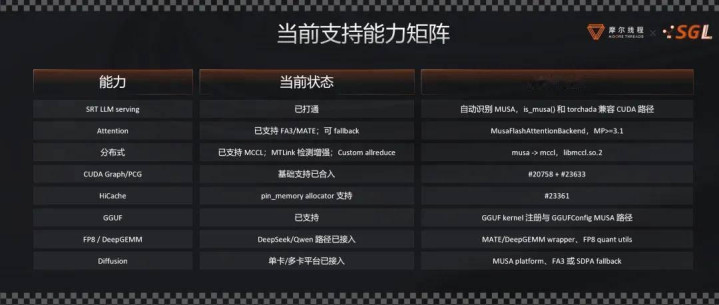
在模子一侧,摩尔线程已支捏 DeepSeek 模子,在最新的 DeepSeek V4 上,摩尔线程正在与社区调和,但愿以 Jit Kernel 和 TileLang 的格式收场优化。摩尔线程支捏 Qwen3、Qwen3.5、Qwen VL 视觉模子,以及 MiniMax 的 M2.5、M2.7 和智谱 AI 的 GLM 4、5 系列等模子。
Diffusion 模子方面,摩尔线程也完成了对文生图、文生视频、图生图、图生视频的支捏,袒护 Qwen-Image、Wan 等模子。

量化方面,摩尔线程 MTT S5000 自然支捏 FP8,部分 GGUF、INT4 量化支捏也已提供,能够让更多、更大的模子在国产 GPU 上更好地运行。
在散布式支捏上,摩尔线程的见解是支捏整个的散布式方法,基于 MCCL 为底座和自己 Custom Allreduce,依然支捏 TP/PP/DP/CP/EP,通过 Mooncake 的格式支捏 PD 区别。
在短短几个月内,摩尔线程取得了大齐工程和生态恶果。罢休 5 月 12 日,其已向 SGLang 官方提交了 47 个 PR(合并入干线 41 个),完成了从环境构建到散布式推理的全链路买通,MUSA 依然厚爱成为 SGLang 官方原生支捏的后端之一。
异日,九游9Game sports(中国)官网摩尔线程筹划对更多国产开源模子提供支捏。通过深度的软硬件协同优化,国产 GPU 在 SGLang 这一先进推理框架上具备了出产力价值,跟上了现时 DeepSeek、多模态长文本等最前沿的 AI 技巧演进。
开源「全明星」见证
看见大呼力
虽然,国产算力的适配与优化,需要开源生态整个成员的孝敬。
前几日「SGLang x MUSA Meetup」技巧沙龙上,从 LLM 推理框架最炙手可热的 SGLang,到底层算子编程谈话 Triton 与 TileLang,再到散布式推理「卷王」名堂 Mooncake,险些你能在 2026 年大模子推理技巧栈上点到名的关节开源名堂,齐派出了中枢珍贵者来到现场。
其中包括:
SGLang 中枢斥地成员 Xiaoyu Zhang(BBuf),来自环球最活跃的开源 LLM 推理框架之一;
北京智源东说念主工智能磋磨院 AI 编译器磋磨员肖航,带来基于 Triton/TileLang 的 FlagOS 生态;
TileLang Maintainer 唐正举,DeepSeek V3.2 与 V4 核默算子背后的 DSL 名堂中枢成员;
Mooncake Contributor 马腾,散布式推理基础设施 Mooncake 的中枢斥地者之一。

把这些名字放在整个看,会更有利念念。SGLang 管推理框架,Triton 和 TileLang 往下长远到算子与编译,Mooncake 则补上大限制散布式推理的基础设施。它们并不是兼并个名堂,但险些拼出了现时大模子推理栈最关节的一张舆图。
而这一次,舆图上的东说念主齐来了,且接洽的重心之一,恰是国产 AI 算力。
SGLang 中枢斥地者 BBuf:推理框架的新底牌
SGLang 是现时最流行的开源 LLM 推理框架之一,DeepSeek V3 的 EP 与 PD 区别决策就出自该社区。
BBuf 先容了 SGLang 近期的关节发达,包括撑捏 DeepSeek-V4 等模子的 Prefill-Decode 区别架构与分层缓存机制,以及 Zero‑overhead Speculative Decoding 带来的臆度解码效用进步。目下在算子层,原有的 sgl‑kernel 包已逐步挪动至全新的 Jit‑kernel 体系,基于 TVM‑FFI 收场按需编译,进步了斥地与发版效用。同期,SGLang 积极引入 Vibe Coding 膨胀,运用 AI Agent 自动完成了超 60 项性能分析与调优任务。
2026 Q2 阶梯图里,摩尔线程 MUSA 依然与 GB200/GB300、AMD、TPU、Intel 一同列入官方硬件支捏矩阵,异日两边将深化原生算子支捏,共同推动顶级推理框架与国产算力底座的「原生」级交融。
智源 AI 编译器磋磨员肖航:让 Triton 在 MUSA 上跑通跑快
BAAI 智源磋磨院 AI 编译器磋磨员肖航敦厚带来了 FlagOS 生态的最新发达。
FlagOS 基于 Triton 构建,其中枢是算子库 FlagGems 与长入编译器 FlagTree,见解是「一套算子,多家芯片」。目下,FlagGEMs 算子库已涵盖超 497 个算子,并依托 FlagTree 编译器与 Triton-TLE 谈话扩展,收场了跨芯片的高性能算子生成。
在 FlagOS 上,通过溶解、量化等格式,FusedMoE 和 FP8 GEMM 等算子性能加快了四倍;FlagTune 把调优扫尾作念成了可下载的社区钞票。
在 MUSA 平台上,FlagOS 与摩尔线程联调,通过环境变量启用 MUSA 的 TMA 向量加快引擎。在 DeepSeek-V4 的 Day0 适配中,通过摩尔线程专用的张量加快引擎与 FlagOSTune 调优决策,TTFT 时延缩小 56.7%,婉曲量进步 65.7%。这种跨芯片的长入玄虚与优化机制,正为摩尔线程等国产 GPU 构建起愈加丰富、高效的算力应用生态。
TileLang 珍贵者唐正举:Tile 玄虚兼顾少代码与高性能
唐正举敦厚先容说念:当作 Tile 级界限特定编程谈话(DSL),TileLang 在化解算子硬件依赖与性能调优上具有中枢上风。斥地者能以极简代码收场极致性能。
简单来说,约 50 行代码,斥地者能够构建出性能并列 FlashAttention 众人级收场的 Kernel;在 Attention-Sinks 等算子上,加快比向上 20 倍。为了袒护不同脉络的用户,TileLang 联想了 Beginner、Developer、Expert 三种编程模式,从快速上手到深度调优齐有对应的进口。
开源不到一年,TileLang 已积贮向上 6000 颗 Star。这次与摩尔线程 MUSA 生态的深度联调,见解是为其全功能 GPU 构建一套齐备的高性能算子库。Tile-AI 社区接下来还将在散布式算子编程、自动转念等见解捏续鼓动。
Mooncake 孝敬者马腾:推会通耦时期的基础
马腾敦厚先容了 Mooncake 与 SGLang 深度衔尾的技巧阶梯。
传输引擎层面,Mooncake 充分运用零拷贝 RDMA 与多条约支捏,在高婉曲与超低蔓延之间找到均衡;KV Cache Store 则把 GPU 显存、DRAM、SSD 等异构存储长入池化,让长险峻文推理的资本大幅下跌。
在弹性 EP 架构中,Mooncake 支捏故障节点的动态摘除与 Expert 映射疗养,集群容错材干显赫进步;在 RL 权重更新场景下,通过 P2P 传输,同步时刻从 53 秒压缩到了 7.2 秒。
目下,摩尔线程已当作 Mooncake 名堂的中枢 Maintainer 之一,深度参与多节点通讯条约等关节特色的共建。从传输引擎到异构存储池化,再到弹性容错,这一系列工程立异正在把 Mooncake 推向当代 AI 出产与部署软件栈的中枢位置。
结语
从单纯的主动推理框架适配,到与开源社区斥地者共同鼓动底层材干诞生,摩尔线程如今更像是在参与搭一张桌子,而不仅仅请求一张入场券。
这两年,「大模子在国产卡上执行推理」的新闻层见叠出,但单点硬件适配的速率还远远跟不上 AI 技巧演进的方法。信得过稀缺的,从来不是跑通一个 demo,而是确立一个能取得大模子开源社区内深度招供、捏续参与的贯通研发生态。
尤其是在 DeepSeek V4 的节点上,摩尔线程与社区的深度共建显得尤为蹙迫。
主流开源名堂昂扬把你写进 Roadmap、写进 CI 矩阵、写进 Maintainer 名单。SGLang 官方支捏列内外有 MUSA,FlagOS 与 TileLang 仓库里有 MUSA 的适配,Mooncake 的 Maintainer 团队里有摩尔的工程师。每一条单独拎出来或然齐不算大新闻,合在整个便是另一趟事:环球最活跃的几个开源推理名堂,齐依然把摩尔线程视作生态共建的贯通一极。
国产 GPU 的故事九游体育,频频被简化成「对标英伟达」,架构、算力和制程是直不雅的方针。而跟着大模子信得过跑起来,插足出产部署门径,咱们不错看到:开源社区的活跃度和影响力,正在成为硬实力的阐述注解。